在日常生活和工作中,我们经常会遇到需要从视频中提取文字信息的需求。然而,传统的方式要求人工耗费大量时间来转录视频中的声音。为了提高效率和准确性,近年来,以视频识别声音提取文字的技术不断发展并得到广泛应用。本文将重点介绍这一技术的关键步骤和实际应用。
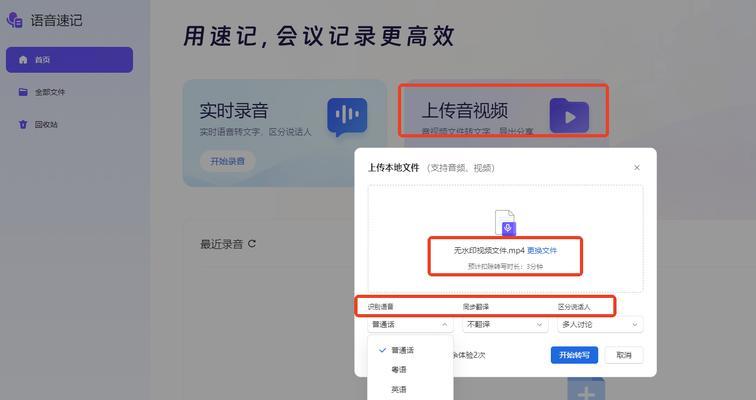
一、视频处理与分析的基础知识
通过对视频进行预处理和分析,可以提高声音文字识别的准确性。包括帧差法、背景建模、光流法等技术,关键是对图像序列进行运动分析和图像特征提取。
二、深度学习在视频声音文字识别中的应用
利用深度学习模型,可以对视频中的声音进行自动识别和文字提取。首先通过卷积神经网络提取图像特征,然后结合循环神经网络对声音进行分类和文本生成。
三、语音识别技术在视频声音文字识别中的应用
语音识别技术是视频声音文字提取的核心步骤之一。通过语音信号的特征提取、模型训练和解码等过程,将声音转化为可识别的文字信息。
四、数据集的构建与标注
为了训练和评估视频声音文字提取模型,需要构建大规模的标注数据集。包括采集视频数据、进行人工标注和数据清洗等步骤。
五、模型训练与优化
通过大规模数据集的训练,可以得到高精度和鲁棒性的视频声音文字提取模型。同时,还需要进行模型参数的优化和调整,以适应不同场景和背景噪声。
六、应用场景与案例分析
视频声音文字提取技术已经在很多领域得到了广泛应用,例如视频字幕生成、视频版权保护、自动化会议记录等。通过分析这些应用场景,可以更好地理解该技术的实际应用价值。
七、算法性能评估与指标分析
为了衡量视频声音文字提取算法的性能,需要定义一些评估指标,例如准确率、召回率、F1值等。同时,还可以通过与其他相关技术的对比实验,评估算法的优劣。
八、挑战与未来发展
尽管视频声音文字提取技术取得了一定的进展,但仍然面临着一些挑战,如多样性场景下的识别问题、语音情感识别等。未来的发展趋势包括更加高效的算法、更大规模的数据集和更广泛的应用场景。
九、安全和隐私保护问题
视频声音文字提取技术在一定程度上可能涉及用户隐私和版权保护等问题。对于数据采集和使用过程中的安全性和隐私性需要重视,并制定相应的政策和规范。
十、学术界与产业界的合作与创新
学术界和产业界之间的合作与创新是推动视频声音文字提取技术发展的重要力量。通过跨界合作和资源共享,可以加速技术研究和应用落地。
十一、国内外研究机构和公司的进展与案例分享
众多研究机构和公司已经投入到视频声音文字提取技术的研发和应用中。通过介绍国内外的进展和成功案例,可以了解该技术领域的最新动态和应用成果。
十二、行业规范与政策引导
为了促进视频声音文字提取技术的健康发展,需要建立相关的行业规范和政策引导。例如,明确数据采集和使用的法律法规、隐私保护政策等。
十三、用户体验与应用价值分析
视频声音文字提取技术的应用价值主要体现在提高效率和准确性方面。通过用户体验和用户反馈,可以评估技术的实际效果,并优化相关算法和模型。
十四、未来发展趋势与展望
随着人工智能技术的不断发展和普及,视频声音文字提取技术也将得到更广泛的应用。未来,该技术有望在各个领域产生更大的影响和价值。
十五、
通过本文的介绍,我们了解到视频识别声音提取文字是一项关键技术,可以通过深度学习和语音识别实现。该技术在各个领域都有广泛的应用前景,但仍然存在一些挑战和问题需要解决。我们期待未来的发展,以实现更高效、准确和安全的视频声音文字提取。